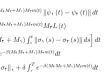یادگیری عمیق در ترجمه – یک مدل بازنمایی برداری کلمات برای ترجمهی ماشینی انگلیسی به فارسی با استفاده از یادگیری ژرف
A Vector Representation Model of Words for English to Persian Machine Translation by Using Deep Learning
یادگیری عمیق در ترجمه
دریافت بخشی از فایل![]()
چکیده
یادگیری عمیق در ترجمه . یادگیری ژرف رویکرد جدیدی در حوزهی یادگیری ماشین است. یادگیری ژرف دیدگاه نوینی برای ترجمهی ماشینی فراهم کرده است. این دیدگاه به ترجمهی ماشینی عصبی معروف است. آموزش یکپارچهی این سیستمها برای ترجمهی ماشینی انگلیسی به فارسی.، نیاز به پیکرهی متنی موازی بزرگ دارد. متاسفانه در زبان فارسی چنین پیکرهی متنی بزرگی در دسترس نیست. به عنوان یک راهحل جایگزین، پیکرهی متنی بزرگ فارسی.، برای بازنمایی برداری کلمات جمعآوری شد.
برای بازنمایی برداری کلمات از روش .Word2Vec. استفاده شده است. مجموعه آزمونی برای ارزیابی بازنمایی برداری کلمات با استفاده از معیار شباهت کسینوسی تعریف شد. با توجه به نتایج به دست آمده از آزمایشها، پارامترهایی که در بازنمایی برداری کلمات به روش .Word2Vec. تاثیر داشتند عبارتند از.: حجم مجموعه دادهها و بُعد بردار ویژگی. هر چه بُعد بردار بالاتر و حجم مجموعه دادهها بیشتر باشد.، بازنمایی بهتری خواهیم داشت. برای پیادهسازی سیستم ترجمهی ماشینی عصبی از مدل دنباله به دنباله استفاده شد و ورودی سیستم ترجمه را با بازنماییهای حاصل از روش .Word2Vec.، مقداردهی اولیه کردیم. آموزش مدل پیشنهادی برای ترجمه، .45. ساعت طول کشید و پس از آموزش مدل به سرگشتگی .29. رسید.
فصل اول: کلیات پژوهش 1
1-1-مقدمه 1
1-2- تاریخچهی ترجمهی ماشینی 3
1-3-تعریف مساله 9
1-4- اهمیت و ضرورت پژوهش ……………………………………………………………………………………….10
1-5-اهداف و پرسشهای پژوهش 11
1-6-ساختار پایاننامه 12
فصل دوم: مبانی ترجمهی ماشینی عصبی 13
2-1-مدل زبانی 13
2-1-1- مدل N-gram………………………………………………………………………………………………..14
2-1-2- مدلهای زبانی مبتنی بر شبکههای عصبی ……………………………………………………..15
2-1-3-ارزیابی مدلهای زبانی……………………………………………………………………………………17
2-2-شبکهی عصبی بازگشتی 18
2-2-1-مدلهای زبانی بازگشتی مبتنی بر شبکههای عصبی بازگشتی……………………………21
2-2-2- یادگیری بر پایه پسانتشار خطا …………………………………………………………………….23
2-2-3-الگوریتم پسانتشار خطا برای شبکهی عصبی بازگشتی……………………………………25
2-3-LSTM 30
2-3-1-آموزش LSTM ……………………………………………………………………………………………38
2-3-1-1-الگوریتم پسانتشار خطا برای LSTM …………………………………………………..38
2-4-ترجمهی ماشینی عصبی…………………………………………………………………………………………40
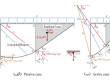
2-4-1-معماری رایج شبکههای عصبی بازگشتی برای ترجمهی ماشینی………………………..42
فصل سوم: بازنمایی برداری کلمات 51
3-1- یادگیری ژرف 51
3-1-1- یادگیری بازنمایی 53
3-2- بازنمایی برداری کلمات 53
3-2-1- بازنمایی برداری پیوسته کلمات 55
3-3-بازنمایی برداری کلمات به روش Word2Vec ………………………………………………………..59
3-3-1-معماری CBOW 60
3-3-2- معماری skip-gram 66
فصل چهارم: روش پیشنهادی و ارزیابی و نتایج آن 69
4-1-روش پیشنهادی 69
4-2-مجموعه دادهها……………………………………………………………………………………………………..72
4-2-1-پیکره همشهری دو 72
4-3-3- پیکره موازی انگلیسی-فارسی میزان 72
4-3-4- پیکره موازی انگلیسی-فارسی تهران 74
4-3-1-پیشپردازش مجموعه دادهها 75
4-3-پارامترهای مهم یادگیری در روش Word2Vec 76
4-4-ارزیابی بازنمایی برداری توزیع شده کلمات فارسی 77
4-5-نتایج و تحلیل بازنمایی برداری توزیع شده کلمات فارسی…………………………………………81
4-6-پیادهسازی مدل دنباله به دنباله برای ترجمهی ماشینی عصبی …………………………………85
4-6-1-نتایج سیستم ترجمهی ماشینی عصبی………………………………………………………………87
فصل پجم: نتیجهگیری و کارهای آینده 89
6-1-پیشنهادها و کارهای آینده 90
مراجع 103
کلمات کلیدی
بازنمایی برداری کلمات , ترجمه ماشینی عصبی , یادگیری ژرف , یادگیری عمیق , پردازش زبان طبیعی , vector representation of words , word2vec , neural machine translation , deep learning , natural language processing
1. اسکویی، م. ا؛ و قاسم زاده، م. (1395). کاربرد قواعد کشفی و الگوریتم ژنتیک در ساخت مدل ARMA برای پیشبینی سری زمانی. نشریه مدیریت فنآوری اطلاعات، شماره 1، دوره 8، صفحه 1-26.